
“Gradient descent can do it.”
These were the words of Sam Altman following the release of GPT-4, as though he were leading humanity into a new world where human productivity would soon be obsolete.
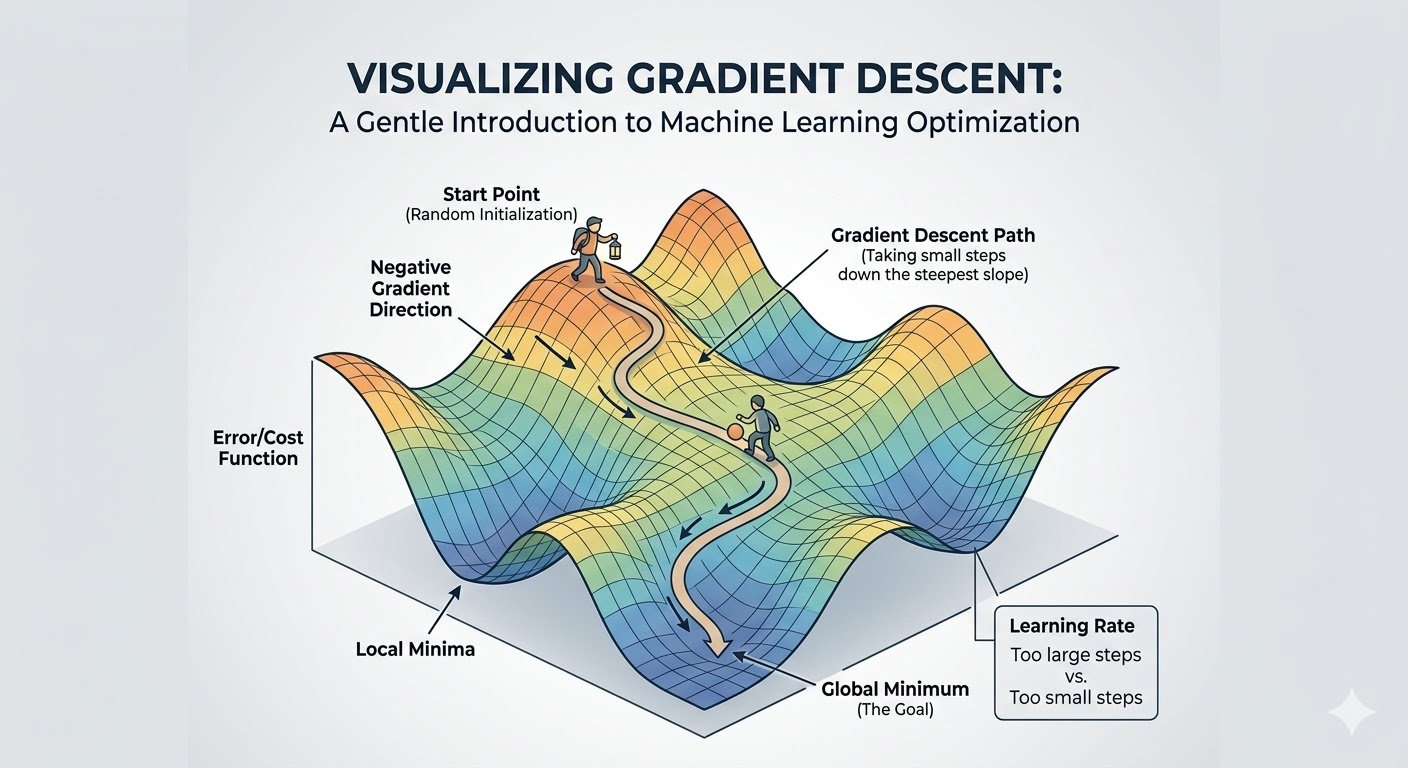
His reference was to an algorithm essential to machine learning; a type of corrective feedback mechanism called gradient descent where a model being trained attempts to minimize the loss between an expected set of outputs and what the model actually produces. The loss, or difference between the expected and ideal output can be thought of as a slope that spans many dimensions; some directions take you higher, eg further from an ideal outcome and some move you lower to more and more optimal results. The goal of the algorithm is to adjust the parameters of the base model through training to traverse down this “gradient” to the point of minimal loss. This represents the ideal output that a machine learning model can produce and is at the core of how most modern machine-learning techniques are structured.
2023 was a time of great optimism from those in the computer science community. This was a time when language models were just starting to break onto the scene following the publication of the Transformer architecture and were finally starting to be viewed as a technology with real-world applications instead of an academic novelty. OpenAI had produced a small language model called GPT-2 several years back, which was significantly outperformed by GPT-3 only a few years later. GPT-4 followed, significantly outperforming them both. A large amount of the performance gains stemmed from using similar techniques but scaling the number of model parameters, or nodes, used in the model network and the compute used to train the network. Innovations in computing hardware such as larger graphics cards with more onboard memory allowed training these networks in a massively-parallel way which had not been previously possible up to that point. There was an incredible optimism in the Tech community that humanity had just delivered AGI and that larger and larger language models would be the vehicle in which humans were comprehensively bested by machines.
It was hard to argue with the logic at the time. Benchmarks for GPT-4 showed that it demonstrated expertise similar to a human across many fundamental measures of what we consider intelligence. GPT-4 was the first large language model to come within striking distance of expert human scores on the SAT, LSATs, AP exams, and even professional exams like the BAR. There was a sentiment that increasing the number of parameters in a language model produced an emergent property that looked and felt like human intelligence. Previous techniques before the emergence of the transformer were only able to produce models which sounded reasonable but were not based in any kind of factual understanding of the text they produced. Language models had a distinct advantage in that almost all of human intelligence is encoded in language in some form. That meant that once the fundamental techniques for machine learning were solidified with neural networks and the transformer, there was a massive quantity of data to train these models. As they model more and more language in the form of books, websites, and social media they necessarily acquired part of the intelligence that human users possessed to create this content. Major voices in the tech community were sounding the alarm that these models could rapidly get out of hand, and that recursive self-improvement through training techniques would turn these into more than just chatbots which were capable of retrieving information from training data.
“I don’t think it’s accurate to think of large language models as a chatbot or like some kind of a word generator. " - Andrej Karpathy
And yet, several years later in 2026 the Singularity still hasn’t occurred. Language models have been improved significantly, with enterprise models such as GPT-5 and Gemini 3 scaling to massive numbers of parameters and being given multimodal capabilities such as image and audio understanding. Despite this, there have been diminishing returns obtained purely through brute-force increases in the sizes of models used in training. We have discovered that significantly smaller models can actually be used which perform similarly and retain most of the intelligence of larger foundational models but require only a quarter of the size or less. Techniques like quantization of weights have shown that we can take 16-bit training weights and reduce them to 4 bits per node while only sacrificing 10-20% of the performance of these models. Techniques such as Retrieval Augmented Generation (RAG), Tooling, and integrated web search have allowed models to pull from data outside of their training to provide more current and accurate responses. All of these improvements have allowed language models to progress to the point where they can be used as savvy AI agents, doing tasks such as sending emails, writing code, answering questions, and serving as domain experts across a variety of different fields. The focus has shifted to making models more efficient, more accurate, and more capable instead of merely scaling size.
So why didn’t this technology go asymptotic? There are a few reasons, but one of the key ones is that most LLMs do not have mechanisms for recursive self-improvement. The “learning” happens during the training stage, and the weights can be adjusted slightly following this training through techniques like Low-rank adaption (LORA) and through adjustments in the form of reinforcement learning with human feedback (RLHF). Even with these techniques, models generally need to be retrained with more or newer data in order to gain new capabilities. A key component of what qualifies humans as intelligent is our ability to continuously learn and improve from every experience. LLMs are still limited in this regard, and most do not have this type of active feedback loop that continuously retools their weights in the way that humans do in their interactions.
A second reason has to do with limitations in terms of the amount and quality of data available. Early models were trained using large swaths of text collected from the internet. This could be accurate or inaccurate depending on the source, and data quality was initially a large issue in the training sets for language models. However, even when data has been cleaned and validated there is still only so much of it available; producing large and high-quality datasets still remains a real problem.
But perhaps the biggest problem is the speculation that we have hit the fundamental limits of the technology. The transformer utilizes a mechanism called “Attention,” where it is trained to pull information from its historical context to best address the current text it receives. This has been an incredibly useful architecture for machine learning models but likely does not capture all of the complexity that occurs with a neural network such as the human mind. It will likely take further advances in theoretical research to truly reach AGI, with language models serving as a powerful stepping stone in getting to this point.
Related Posts

Vitality, header-only VITA 49 for C++
Anyone who has spent time in the world of software-defined radio knows that…

Modern Trends in Software-defined Radio
I'm old enough to remember the "good old days" of when radios and RF technology…

Ollama-hpp, header-only language models in C++
The democratization of open-weight, locally-run language models has been one of…
